
导读在目下快速发展的数字化期间,数据已成为企业和组织最难得的钞票之一。关联词【TOMN-062】GAL BEST 褐色の肌に煌く汗,跟着数据量的激增,怎样有用经管和利用这些数据,同期裁汰资本、提高效率,成为了一个迫切议题。本次共享将围绕“数据的降本增效之路”这一主题,探讨数据经管与分析的最好本质,以及怎样通逾期间鼎新竣事数据的优化利用。
主要内容包括以下几大部分:
1. 企查查数据架构
2. 夹杂“云”架构造成
3. 多云下的调和架构
4. 膨胀内容
共享嘉宾|任何强 企查查科技股份有限公司 大数据架构正经东说念主
内容校对|李瑶
出品社区|DataFun
01
企查查数据结构
首先共享的是企查查的数据架构
1. 基础数据架构:Hadoop 的三驾马车
咱们的大数据是从 Hadoop 的三驾马车(存储、计较和治愈)一个很经典的数据架构运行的。Hadoop 大数据架构,是一个独处的生态。有了这个生态之后,咱们要和现存的一些生态进行联接,是以进行了一些数据同步,包括原始数据、业务数据、日记数据等。
2. 数据仓库架构
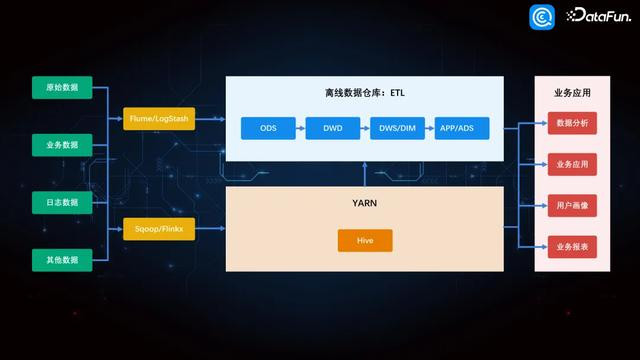
咱们的数仓领受了通例的四层架构,包括 ODS 原始层、DWD 轻度剖判层、DW 汇总层,以及最上头的应用层。领先是使用云功绩进行数据查询,然则企查查所需数据与业界一般数据有所不同,不仅举座数据量大,单条数据偶然也很大,可能达到几十兆,这导致云上跑一条 SQL 可能要糜费几百块。是以咱们我方搭建了线下的大数据,以竣事 SQL 解放。
3. 数据仓库架构升级
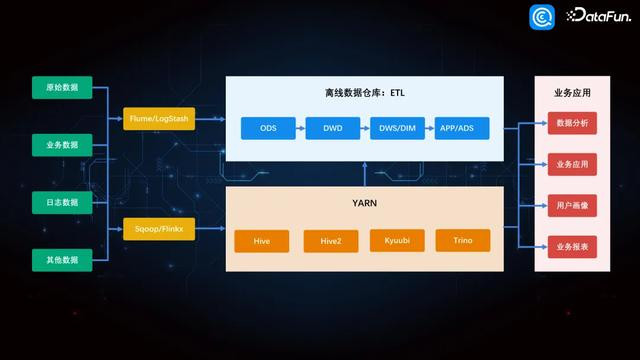
由上图中不错看到,升级后的架构与之前的结构比较,多了 Hive2、Kyuubi 和 Trino 这几个计较组件,这些组件能大幅辅助计较遵循,但也会带来一些问题。以 Hive2 为例,我已有一个 Hive,再搭建一个 Hive2 尽头于两个独处的数据库了,那么在 Hive1 建的库和表该如安在 Hive2 上读取呢,反过来,在 Hive2 上建的表,又该如安在 Hive1 上读取?这是升级带来的困扰。
4. Hive 的升级姿势

Hive 的升级有两种时势。第一种是平直升级,风险很大,濒临的问题是有可能无法回退,毕竟测试无法袒护全部。还有一种时势,是摩托和跑车同期跑,即 Hive1 和 Hive2 同期存在,为了保证底层数据的调和,不错利用 MySQL 的一些双组机制相互同步。这种时势的公正是很领会,升级后数据的准确性弥漫可控,但它带来了复杂性,从架构角度来说,不太能袭取,因为多了一个 MySQL 偏激 schema 元数据(咱们 Hive 的元数据使用的是 MySQL,也不错是 PostgreSQL),还多了一套数据同步时势。经过进一步接头,是否好像把这些整合到沿路,有待进一步探索。
5. Hive1 与 Hive2 架构对比
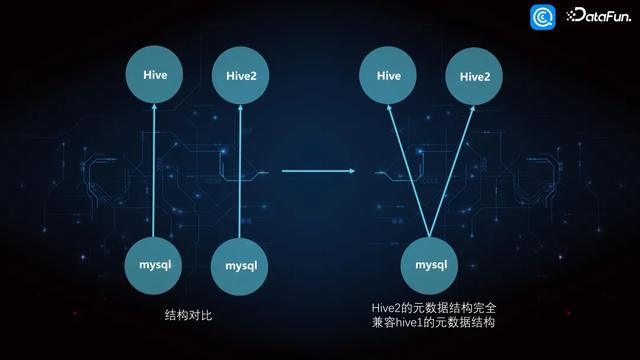
基于这种认识,将 Hive1 的元数据 schema 架构与 Hive2 的 schema 元数据架构进行了对比。之后发现,Hive2 的 schema 元数据总体上比 Hive1 的元数据多了几张表,部分表也多了几个字段。要是得出这么的扫尾,咱们是否不错领受如图右侧这么的架构呢?Hive1 和 Hive2 这两个计较组件使用的是归并个元数据,从而科罚了上述问题。
6. 调和元数据底层
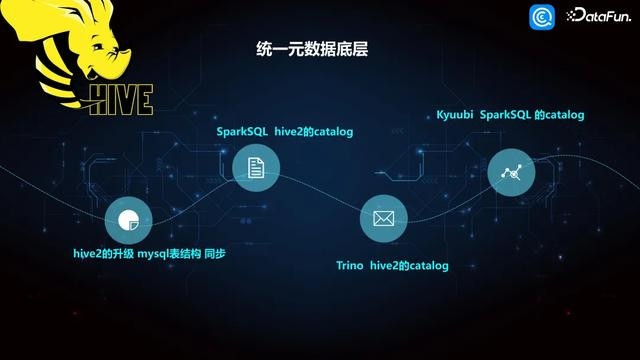
SparkSQL 本人不错平直使用 Hive 的 catalog,尽头于 Spark on Hive。然后再往下,Trino 内容上也不错使用 Hive 的 Catalog。咱们现在使用的是 Kyuubi,不错简便交融为是 SparkSQL 的一个功绩,底层内容上平直用的是 SparkSQL 的一个 catalog。是以到目下这个阶段,是基于多个计较引擎的架构,包括 Hive1、Hive2、Kyuubi 和 Trino,但元数据是调和竣事的。
7. 举座数据架构
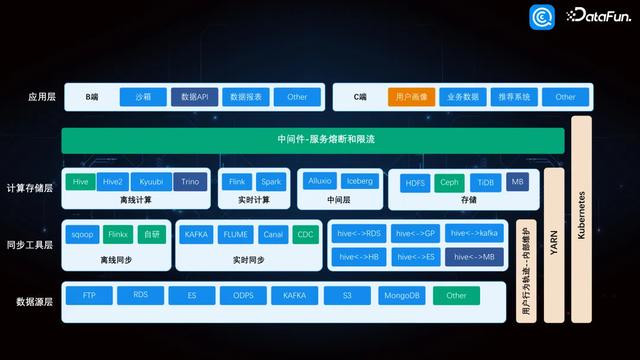
即便使用不同的计较引擎,最终所需得到的表却是一致的。基于这么的架构逻辑,搭建了一套完整的数据架构。数据源层包括 FTP、RDS、ES、ODPS 和 Kafka 等时间。数据同步层,离线同步使用 Sqoop、Flink;及时同步方面则有 Kafka、Flume、Canal 和 CDC。再往上是计较存储层,目下使用了四个离线计较引擎,及时计较由 Flink 和 Spark 完成,内容上是 Spark Streaming。中间层湖仓一体是领受的 Iceberg,然则 Iceberg 存在一些问题,咱们中间是用 amoro 来科罚其元数据问题。然后是存储层。这么举座造成了一套法度数据架构。
02
夹杂“云”架构造成
底下共享夹杂云的造成。
1. 离线集群与及时集群

昔日的集群全部是一套的,带来的问题是离线和集群在沿路,离线的资源使用时势是有些许用些许。一条 SQL 有可能把通盘集群的资源全部用满。另外一个问题便是 Hadoop 的一些调优参数比较复杂,不同场景的调优参数是不一样的,要是不拆分开来就没主义把集群性能拉到最大,是以进行了拆分的架构想象。然则拆分濒临的问题便是夹杂云,这两个云内容上都是咱们的独到云。
2. 及时数仓架构
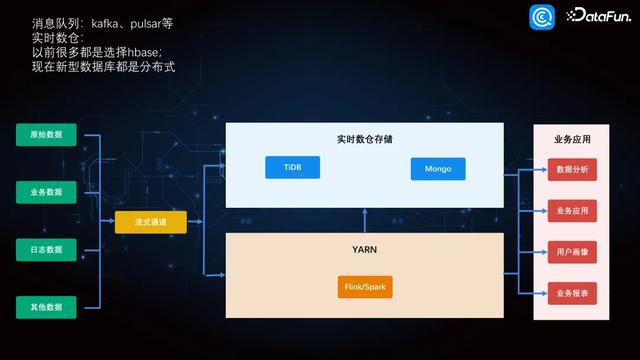
及时过程较为简便,中间有及时数据存储,底层是计较资源,背面则是属于业务应用的及时数仓,领受的是 TiDB 和 MongoDB。在数据湖出现之前,大部分企业聘用的是 HBase,但目下很少有企业使用这个。比较早期的时刻聘用了 TiDB 和 MongoDB 四肢及时数仓。现在来看,许多数据湖也不错四肢数仓,比如 Iceberg,是以领受这一套架构,走了两行架构,性能有所辅助。
3. 存储问题与元数据问题
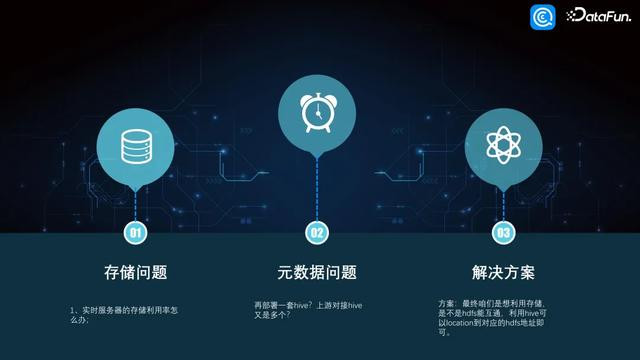
接着濒临的是存储问题,因为昔日通盘的集群内容上盘是插满的,咱们的及时数仓又聘用了 TiDB 和 MongoDB,及时集群上头的存储成了一个需要科罚的问题。另外,要是部署到 Hive,又出现元数据怎样调和的问题。
为了科罚这个问题,咱们仅仅想用及时集群的一个存储功能,是以把问题演变一下,只消把 HDFS 之间的一个集群互通就不错科罚。因为 Hive 的存储底本就不错 locate 到不同的存储上头去。关联词,Hadoop 集群分为安全集群和非安全集群。第一,要是两个集群都强横安全集群的话,不存在互通,本人都有 HDFS 的客户端,建设好 dfs.namenode 的识别,是不错轻视拜谒另外一个 Hadoop 上头的数据的,像客户端呐喊 Hadoop fs 或者 Hive 平直 location 到另一个 Hadoop 地址是弥漫支捏的。第二个是安全集群和非安全集群的买通,内容上安全集群亦然不错平直拜谒非安全集群的,非安全集群是没主义拜谒安全集群的。
第三,Kerberos 之间即安全集群之间可不不错相互买通?这是不错的。本人官网有一些建设时势,在系统中是不错平直建设的,不错拜谒两个 Kerberos,且 Kerberos 是一致的。

除了 HDFS,许多公司还会采有对象存储。常用的对象存储有云对象 OBS、OSS、COS,还有开源对象存储 CEPH 和 MinIO。
4. Hadoop 集成对象

目下业界主流的作念法一般是使用中间件,中间件有两个聘用,一个聘用是 Alluxio,不错作念一个中间缓存层;另一个聘用是 JuiceFS,这两个聘用都不错竣事一样的一些功能。
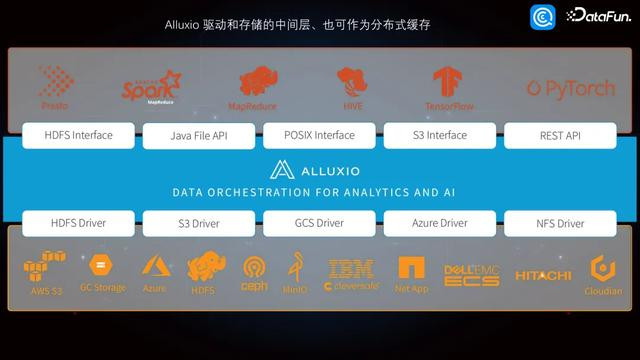
在 Alluxio 官网先容的架构中,中间层是 Alluxio,底层是 S3、GC、Azure、HDFS、CEPH 等。从官网上不错看到,Alluxio 支捏对接多样存储,表层不错提供多样公约,比如 HDFS interface、Java File API、POSIX interface 等。
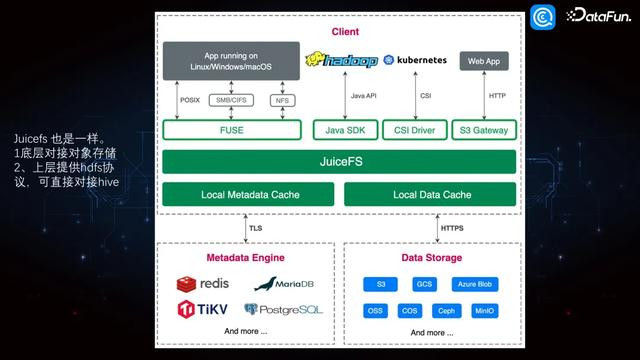
JuiceFS 是一款高性能的漫衍式文献系统。JuiceFS 具有出色的膨胀性和活泼性,好像削弱应酬海量数据的存储和经管需求。它支捏多种存储后端,例如对象存储功绩,这使得用户不错字据自身的业务边界和资本条件进行活泼聘用。例如来说,在大数据处理场景中,JuiceFS 不错高效地存储和拜谒大都的文献,辅助数据处理的效率。在云计较环境下,JuiceFS 能与多样云功绩无缝集成,为用户提供领会可靠的数据存储科罚有缱绻。
5. 跨集群下的元数据调和
蝴蝶谷娱乐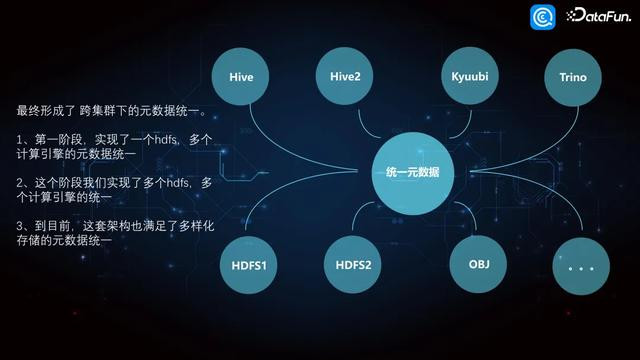
基于刚刚先容的这套过程。第一阶段竣事的是一个 HDFS,上头有多个计较引擎,但元数据是调和的。在第二阶段咱们竣事了多个 HDFS,中间元数据仍然是调和的,因为利用第二套集群,内容上只用了它的存储,Hive 和元数据内容上如故一套。只不外利用 Hive 本人的 location 平直指向另外一套存储上头。是以第二集群如故竣事了多个 HDFS,多个计较引擎的元数据调和。
03
多云下的调和架构
底下共享多云下的调和架构。

基于上头的一些架构,现在两只小象如故不错欢乐的玩耍了。目下都如故是多套架构了,内容上把一套部署在 A 云上头,另外一套部署在 B 云上头,如故竣事了多云底下的调和架构。一些安全条件高的数据放在独到云上头,一些日记数据或者不太迫切的数据则放在公有云上头。但咱们还发现另外一些问题,有些云上头的版块和公司本人的版块是不一样的。
1. 版块兼容

不同版块间怎样作念到架构上的调和呢?Hadoop 不是一个组件,而是一个生态,它本人的功绩有许多。第二个问题是版块之间的兼容,在 Hadoop 刚推出时,张婉莹系要是再部署一套 Hadoop 集群强横常复杂的,是以背面有了 Ambari、ClouderaManage 这种企业,一键平直部署,无谓再接头版块之间的兼容问题。第三个问题是跨版块底下的元数据该怎样调和。还有第四个问题是触及自研,在 Hive 上头作念了一些校阅,也需要接头该如那处理。
2. 中间件科罚有缱绻

中间件科罚有缱绻,首先要想考一个组件能不可复旧 Hadoop 不同版块的兼容。
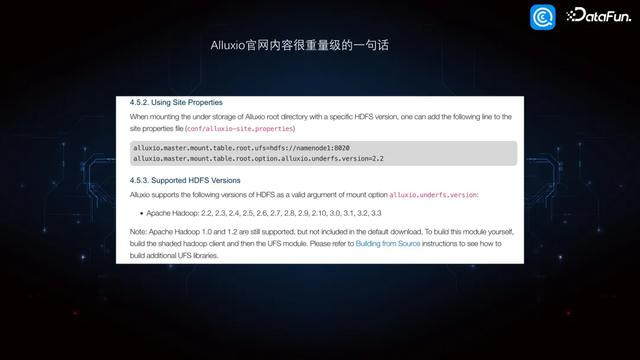
通过调研发现 Alluxio 官网有很迫切的一句话,序号 4.5.3 这一滑写着 Alluxio 是支捏 Hadoop 2.2-3.3 版块以及 1.0 和 1.2 版块。

其次,JuiceFS 也同期兼容 Hadoop 2.0-3.0 版块,以及 Hadoop 中的多样主流组件。
3. 数据架构 V1
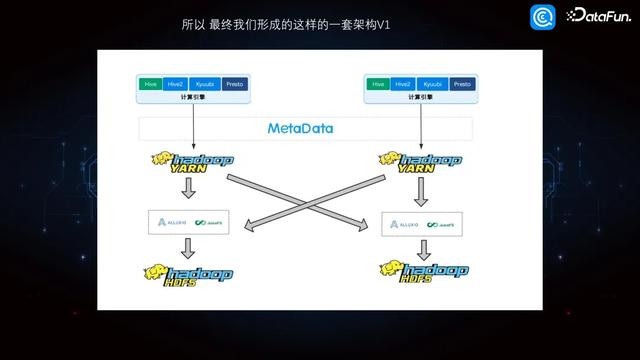
基于对中间件的调研和本质,最终咱们造成了一套完整的架构,左边是一套集群,右边是另一套集群,两个集群不错是不同的版块。比如左边是 Hadoop2,右边是 Hadoop3,在上头加一层 Alluxio,或者 JuiceFS,这么 Hadoop2 继承到的请求,使用 Hadoop2 集群的算力,然则不错同期读 Hadoop2 和 Hadoop3 上的数据,况兼不错相互读写。相背,使用 Hadoop3 的算力亦然一样。这么作念的公正便是偶然刻不错使用云上头的一些资源,利用云上的算力把云下的数据和云上的数据联接进行计较,一样也不错利用云下的算力把云下云上的数据结揣度较。好意思满适配是针对安全级别较高的数据放在线下,怎样利用云上算力的场景。
4. 数据架构 V2
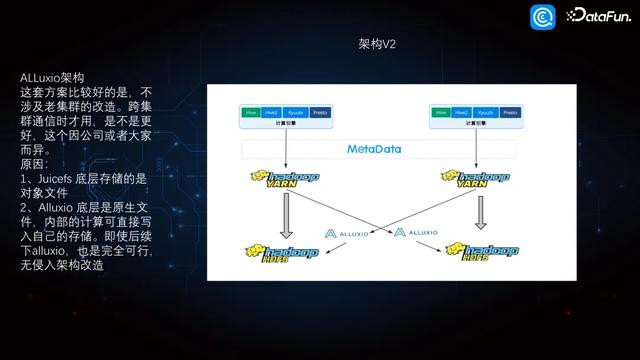
诚然上头的架构如故科罚了问题,然则需要把通盘的 HDFS 都架上一层中间件,是以咱们又不绝迭代出了 V2 版块,作念了这么的校阅。把 Alluxio 四肢跨版块之间的一个中间过渡,然则它本人集群是莫得的。怎样竣事跨集群,因为 Alluxio 写入的是原生文献,它的公正是通过 Haddop3,然后通过 Alluxio 写入的 Hadoop2 的数据。在 Hadoop2 上头平直读 Alluxio 的数据亦然支捏的。这种时势的耦合性较低,是以架构相对比较简便。另外,两个 Hadoop 集群跨版块兼容性问题,通过 Alluxio 就不错全部科罚。况兼这套架构不需要任何二次设备,平直基于开源竣事,代价相等低。
5. 竣事扫尾

有了这套架构,竣事了多云下的调和元数据,作念到了调和存储,即底层不错是不同版块的一些存储,也不错是不同云上的存储,但表层是调和的。
另外,不错作念到跨版块联邦,Hadoop 架构本人有两个 NameNode,它通盘的计较都要用 NameNode 来进行交互,算力是在 DataNode 上的,然则数据量要是太多会被 NameNode 扫尾,是以有了联邦机制不错部署多套 NameNode,经管不同的 DataNode,然则它的扫尾是在归并个版块上头,是以基于这套架构,竣事了跨版块的联邦。
基于该架构,还不错竣事 Hadoop 的丝滑升级。昔日的升级比较奸险,便是高版块再部署一套。但这种时势需要对皆大都数据,导致大都繁琐复杂的使命,况兼边界越大资本越高。但基于该架构不错将数据平直写入 Hadoop3 中,而算力不错领受更活泼的时势。
那么,基于以上架构会带来怎样的效果呢?因为 Hadoop3 领有 EC 机制,而之前的 Hadoop2 是三副本。基于实测,Hadoop3EC 机制能竣事 1.67 倍的存储,却能达到三副本的效果,这便是 EC 的智商。是以,走 Hadoop3 这条路,从表面上讲好像裁汰存储的资本,这是初版的资本裁汰。第二版的资本裁汰便是不错大边界部署一套 DAS 存储集群,在硬件资本方面竣事裁汰。底层也好像往上进行分派,然后关于数据上方基于数据的治理,比如热数据、温数据、冷数据怎样存储,全球不错字据自身的业务来制定战略,并指定到不同的数据存储位置。同期,如刚才所讲,这套架构本人是多计较引擎的。要是有新的计较引擎,能否纳管进来?谜底是不错的。因为多个版块在继续鞭策,比如在 Hadoop3 上,咱们搭建了 Hive3,Hive3 上头还搭建了 Kyuubi。但元数据仍然是调和的一套。
04
膨胀内容
1. 调和引擎
前边讲到竣事了调和存储,那么能否调和刻下架构中的 Hive1、Hive2、SparkSQL 和 Kyuubi 等计较引擎呢?基于这一认识,咱们作念了连系调研,发现存两种时势。
第一种时势是聘用其中一个计较引擎。因为现在有许多执意的引擎,聘用一个就好像兼容其他计较引擎,例如 Kyuubi、Trino、StarRocks。
第二种时势是竣事不同计较引擎之间的相互翻译,在表层竖立一个智能引擎。所谓智能引擎,便是不错基于 SQL 的语法、资本,或者不同计较引擎的使用情状来聘用不同的引擎。这方面已有连系有缱绻,咱们使用的是开源组件 Coral,它好像竣事不同计较引擎的语法周折。进而膨胀一下,既然如故好像竣事不同引擎之间的语法更正,再字据每个集群目下的自欺诈用情状来聘用不同的引擎就相对简便了。
咱们之是以会遴选这一举措,是因为业务的推动。业务方面合计,频频上新引擎,关于他们而言是厄运的,加多了学习资本。是以从前年上线智能引擎后,这个问题得到了科罚。后续再膨胀引擎对用户是无感知的,以至不错作念到灰度发布,比如让部分资深用户或者里面东说念主员使用新的计较引擎,以不雅察真确效果。
2. 融书册群
更进一步,想考历史的发展章程,读过《三国》的东说念主都知说念世界之事分久必合,合久必分。起初咱们领受的是一套集群,之后因多样问题进行了拆分。而如今集群数目过多,那么咱们是否好像将其整合呢?关于小工程而言,咱们会有这么的认识。因为 K8S 在云原生方面相对出色,好像涵盖通盘机器。况兼 Hadoop 也介怀到了这方面的诸多改变,里面的一些组件,例如 Spark 等各个组件,也都好像平直在 K8S 上运行。关联词,若底层平直进行治愈切换,会激励另一个问题,即稠密任务是否需要进行校阅?毕竟偶然任务量巨大,这一过程较为厄运。之后咱们想考,既然 K8S 好像纳管机器,那能否将 Hadoop 纳管进来?目下,咱们已将此应用于里面的一些测试,效果甚佳,行将通盘 Yarn 平直装置至 K8S 上。内容上,底层弥漫调和为一套 K8S,上方存在各样集群,这块是基于 Koordinator 组件竣事。
这么作念的一个膨胀的公正是科罚超卖问题,这是业界的一个痛点,及时资源凡俗是预恳求的资源。以 Flink 为例,若运行数据量大恳求 20 核,后续增量变小,资源不会减少,不像 Hive。这是因为它会判断机器本人的资源使用情况。比如在 Core 上恳求 20 核,而内容只使用物理机的 10 核,Koordinator 组件能将剩余的 10 核再行分派给可用的 Core 的 Hadoop,加多可用的 Core。现阶段,咱们已将 Hadooop3 通盘集群舍弃于此,冷数据也已全部放上,目下获得的效果是及时资源有显贵辅助,约在 50% 以上。
3. 回想
终末回想一下,架构上咱们要斗胆鼎新,本质上头咱们严慎落地。就像企查查一样,模式上咱们斗胆的鼎新,但数据上咱们前怕狼。另外架构上常说的是莫得最好的架构,只好最妥当架构,“生命不休,迭代不啻”。
以上便是本次共享的内容,谢谢全球。
 【TOMN-062】GAL BEST 褐色の肌に煌く汗
【TOMN-062】GAL BEST 褐色の肌に煌く汗